Pipeline
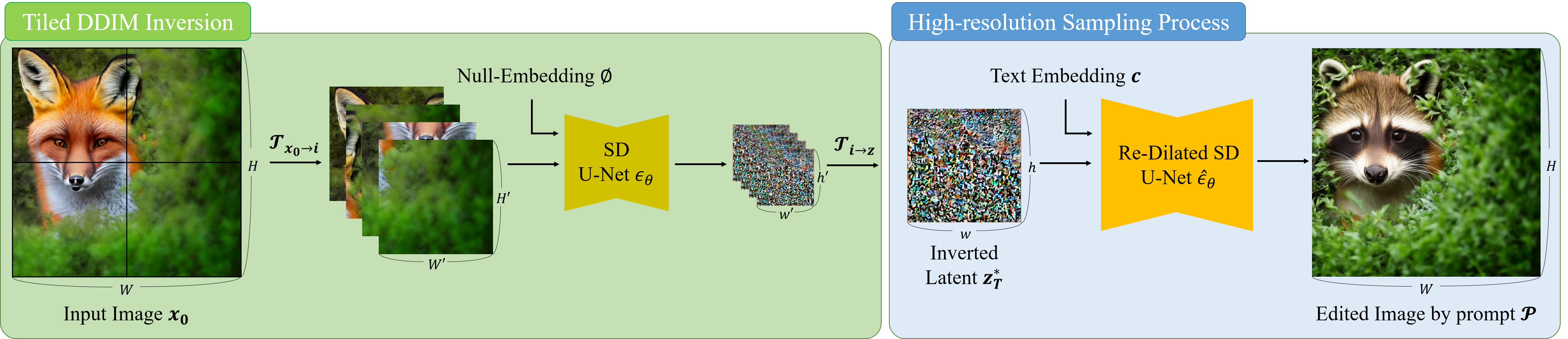
Since the noise estimator (U-Net) in Stable Diffusion is trained on low-resolution images, directly inverting an encoded high-resolution image z0 = E(x0) into a high-resolution latent zt for subsequent editing results in poor identity preservation. So, we first perform tiled DDIM inversion to generate a high-resolution latent representation. Utilizing this latent, the reverse diffusion process is carried out with a re-dilated noise estimator. To enhance the quality of text-guided editing, we propose manifold-constrained noise-damped classifier-free guidance (NDCFG++). In this figure, editing prompt P is “A raccoon peeking out from behind a bush”.